Apache Hive入门二
日期:2014-05-16 浏览次数:20895 次
我的偏见: 以上是我对 Hive Why(为什么使用Hive)片面的观点。 集群中的Hive 多个Hive的物理节点连接到相同的数据库和HDFS环境,防止Hive Thrift Server单点失效(SPFO)问题。 将Hive的MetaData 存储在 MySQL中,MySQL的运行环境支持双向同步或者集群,这样至少2台数据库服务器上热备份着Hive的元数据存储,例如: 多个物理Hive节点的数据内容保存在HDFS上,通过修改 hive-default.xml 配置 文件,指向NameNode节点即可,例如:
? 对于互联网公司来说提炼挖掘生产中用户产生的大量日志是个有价值的工作,在这些看似垃圾东西中蕴含着大量的商业机会和用户的需求,如果可以简单的实现当然皆大欢喜,但是面对庞大的输出日志需要去提炼的时候只好束手无则无视他的存在,就拿我们最熟悉的Log4J来说,如果是上TB的海量文本类型输出的格式根本无法查询,更谈不上数据挖掘。
?? 当然我们也知道存放在数据库里面当然是不错的选择,对抗海量的日志数据存储与查询坚持做下去的话最后换来的是高昂的代价,Hive借助MapReduce的计算+HDFS的海量存储的功能,对与海量的日志存储、查询,数据挖掘Hive也是个不错的选择,在功能上和总体成本上高于刚刚所说的前两者。
?? 但是对与存储在其他类型的NOSQL产品,Hive投入正式生产的环境我们还需要进一步的分析与比较,例如:MongoDB vs Hive,这个2个产品对于海量日志数据挖掘的性能与系统的扩展性来说谁将会比谁更胜一筹喃?因为 MongoDB 中也是支持海量级分布式存储,并且MongoDB也支持了MapReduce算法,这样我就需要为此得出一个结论,或者说我需要一个折中的方案,但不是现在。
?
?? Hive 中不支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。Hive中你添加了数据就无法删除的,SQL的fans们是不是很费解?我是这样认为的就拿Google的Google Analytics分析工具为例子,在Google Analytics分析工具 会有对日志进行删除的操作吗?答案是“NO!”,也许在Hive设计的时候Facebook的工程师就认为对需要进行挖掘的数据删除是一项没有必要的工作,Hive在Facebook能成功,并且运行在上千台的节点上 或许就是Facebook工程师们明确了Hive不去做的事情,让Hive只做好那一部分事情。
?
Hive的失效转发可以设计成这样的,将元数据和存储的数据分别保存在同一个位置,如图所示: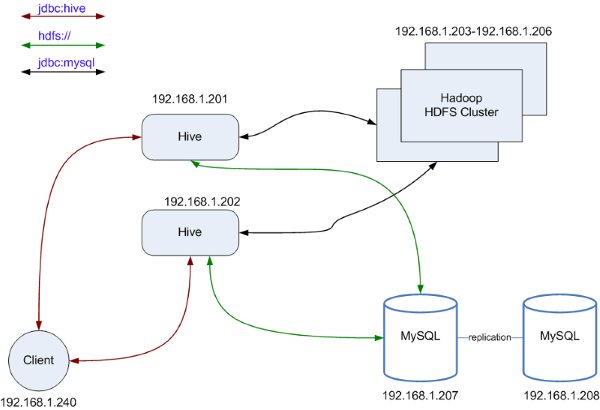
<property>
? <name>javax.jdo.option.ConnectionURL</name>
? <value>jdbc:mysql://192.168.1.203:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
? <name>hive.metastore.warehouse.dir</name>
?? <value>hdfs://serv1:9000/user/hive/warehouse</value>
?? <!– <value>/user/hive/warehouse</value> –>
? <description>location of default database for the warehouse</description>
</property>
Hive 与 Log4J?
在Hive中建一张表叫user_log,里面含有4个字段,以\t划分,一行一条数据,建表的脚本如下:
CREATE TABLE USER_LOG(DateInfo?STRING,LogName?STRING,LogLevel?STRING,MSG?STRING)
ROW FOR
