运用HTMLparser解析HTML
日期:2014-05-17 浏览次数:20681 次
http://express.ruanko.com/ruanko-express_44/technologyexchange6.html
htmlparser是一个纯的java写的html解析的库,它不依赖于其它的java库文件,主要用于改造或提取html。Htmlparser相对于其他html解析工具有较好的优势,它能超高速解析html,而且不会出错。
我用一段代码简单介绍htmlparser的运用方法。
public Node[] getNodes(String htmls, String tagTyp, String charset) {
Parser parser = Parser.createParser(htmls, charset);
NodeFilter filter = new TagNameFilter(tagTyp);
NodeList nodeList;
try {
nodeList = parser.parse(filter);
return nodeList.toNodeArray();
} catch (ParserException e) {
e.printStackTrace();
}
}
|
首先使用流将html内容读取出来,放入解析对象中并设置字符编码,这里我解析的是三大大型招聘网的简历数据,由于每个网站的简历编码方式不同,所以在解析内容的时候需要指定不同的字符编码,而且指定编码集的时候只有通过查找三大网站文件<head></head>中的内容不同而指定字符编码,这是一个让人比较头痛的问题。
代码中的filter对象主要用来过滤标签获取标签中的内容,如:将tagtyp参数替换成<table>那么它会将文件中所有<table></table>中的文本内容获取出来,接下来要做的只要遍历节点集合就可以了。如果节点中还有节点,可以继续更深一层过滤。Htmlparser的主要作用也就在这里。而真正在我的项目中仅仅依靠过滤来达到想要的效果还是有一定距离的,每个html文件的布局不同,解析的流程也就不同,所以不能像一般程序那样方法复用(这里我说的是获取真正想要的内容时,过滤标签的代码还是可以复用的)。而真正获取想要文件内容时还得需要使用关键字匹配的方式来实现。虽然操作比较麻烦,但毕竟可以达到想要的效果。
Htmlparser对html文件的解析处理结构
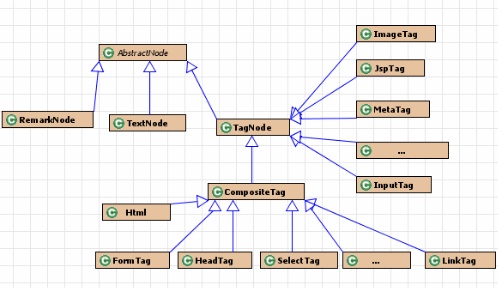
HtmlParser采用了经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面各元素。
org.htmlparser.Node:
- 节点到html文本、text文本的方法:toPlainTextString、toHtml
- 典型树形结构遍历的方法:getParent、getChildren、getFirstChild、getLastChild、getPreviousSibling、getNextSibling、getText
- 获取节点对应的树形结构结构的顶级节点Page对象方法:getPage
- 获取节点起始位置的方法:getStartPosition、getEndPosition
- Visitor方法遍历节点时候方法:accept (NodeVisitor visitor)
- Filter方法:collectInto (NodeList list, NodeFilter filter)
- Object方法:toString、clone
