哈希匹配和嵌套循环的有关问题,期望DBA_Huangzj能回答一下
日期:2014-05-17 浏览次数:20708 次
哈希匹配和嵌套循环的问题,期望DBA_Huangzj能回答一下
我看到http://bbs.csdn.net/topics/390352313这个帖子了,有些相似,悟出这个跟数据量有关系,但是我死活不清楚,跟存的值有什么关系。操作步骤、执行计划与记录数如下
表结构:

执行结果:

行数:366324
表查询语句1:
执行上面查询结果是慢的,执行结果:31秒,返回1019行,执行计划如图:

表查询语句2:
执行结果:0秒,返回21619行,执行计划如图: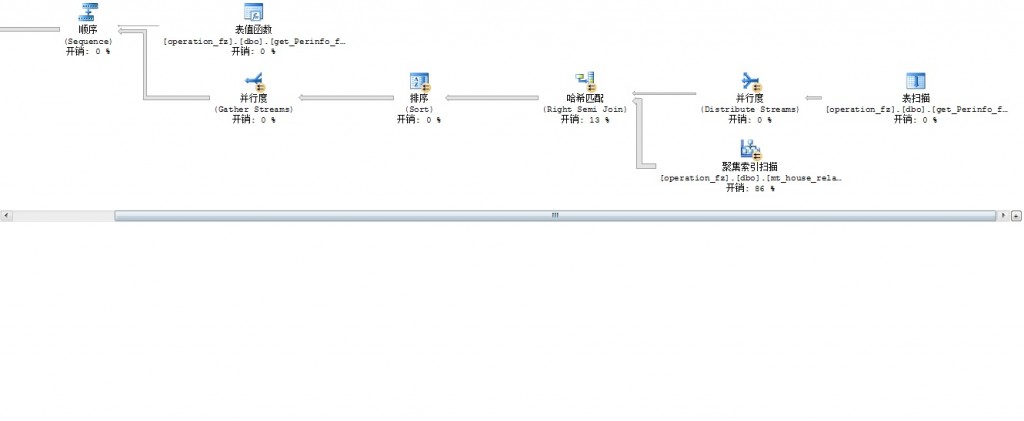
两个条件不同之处是标红部分,我很不理解,为什么一个是哈希匹配,一个是嵌套循环,在什么时候会是哈希匹配,什么时候是嵌套循环,分可以追加,求解释
------解决方案--------------------
DBA兄,你说我答好呢还是不答好呢
------解决方案--------------------
 不看不知道一看吓一跳,给点名了!!!最近公司网络烂,网页都打不开。。。
不看不知道一看吓一跳,给点名了!!!最近公司网络烂,网页都打不开。。。
哈希:主要对大数据量且没有索引或者没有排序的数据进行关联的时候用的,它会在内存中创建一个过度表进行匹配,对大数据量尤为有效。
嵌套循环:对小数据量关联的时候较为有效,而且这个也是3种关联(哈希、合并、嵌套循环)中最常见的一种,由于绝大部分应用中,查询数据都不会说次次都大数据量和没有索引地查询,所以即使哈希有其好处,但是也往往意味着存在一些性能问题,如缺少where条件、缺少索引、返回的数据量过大等,当然,视具体环境而定。在绝大部分应用中,应该比较常见的是合并和嵌套循环。
查询中1的表,应该是历史表或者你通过select * into弄出来的吧。
先假设这两个表的数据量和结构完全相同,仅仅是测试对比的。不然基本上没啥可比性。
先来说说数据分布的问题,从执行计划上看到有聚集索引,那么你的表是有顺序的。如果你所需的数据基本上都在表的前面,那么扫描范围就小,查找速度就快,如果极端情况下都在表的尾部,那么要扫描到后面才能返回所需的数据,自然就慢。这种情况下保持统计信息的及时更新和在那个列上创建非聚集索引“可能”对查询有帮助。这跟同一个查询语句,只是order by一个列,一个是desc一个是asc相类似。这时也经常会出现性能差异。
再看一次你的执行计划,然后百分比主要在关联,但是我个人认为是函数惹的祸,你看第一个查询的执行计划,那个函数处理的表没索引,而且数据量大(看箭头的粗细,1000多行就那么一点,估计那个函数处理的表应该有10万级别),扫描这么大个表,又没有索引辅助,慢是很正常。
另外第二个查询用到了并行度,也就是这个时候可是借助多CPU来计算,对速度提升也有一定程度的帮助。
------解决方案--------------------
http://www.cnblogs.com/CareySon/archive/2013/01/09/2853094.html
我看到http://bbs.csdn.net/topics/390352313这个帖子了,有些相似,悟出这个跟数据量有关系,但是我死活不清楚,跟存的值有什么关系。操作步骤、执行计划与记录数如下
SELECT *
FROM mt_house_relationPer_tbl_zq20130308
ORDER BY hou_client asc
表结构:
执行结果:
行数:366324
表查询语句1:
select a.id
from mt_house_relationPer_tbl_zq20130308 a
where
exists( select id from get_Perinfo_fordept_fun('67,91',3 ) as getPer where del=1
AND hou_client= getPer.id )
order by a.id desc
执行上面查询结果是慢的,执行结果:31秒,返回1019行,执行计划如图:
表查询语句2:
select a.id
from mt_house_relationPer_tbl a
where
exists( select id from get_Perinfo_fordept_fun('67,91',3 ) as getPer where del=1
AND add_per= getPer.id )
order by a.id desc
执行结果:0秒,返回21619行,执行计划如图:
两个条件不同之处是标红部分,我很不理解,为什么一个是哈希匹配,一个是嵌套循环,在什么时候会是哈希匹配,什么时候是嵌套循环,分可以追加,求解释
------解决方案--------------------
DBA兄,你说我答好呢还是不答好呢
------解决方案--------------------
不看不知道一看吓一跳,给点名了!!!最近公司网络烂,网页都打不开。。。哈希:主要对大数据量且没有索引或者没有排序的数据进行关联的时候用的,它会在内存中创建一个过度表进行匹配,对大数据量尤为有效。
嵌套循环:对小数据量关联的时候较为有效,而且这个也是3种关联(哈希、合并、嵌套循环)中最常见的一种,由于绝大部分应用中,查询数据都不会说次次都大数据量和没有索引地查询,所以即使哈希有其好处,但是也往往意味着存在一些性能问题,如缺少where条件、缺少索引、返回的数据量过大等,当然,视具体环境而定。在绝大部分应用中,应该比较常见的是合并和嵌套循环。
查询中1的表,应该是历史表或者你通过select * into弄出来的吧。
先假设这两个表的数据量和结构完全相同,仅仅是测试对比的。不然基本上没啥可比性。
先来说说数据分布的问题,从执行计划上看到有聚集索引,那么你的表是有顺序的。如果你所需的数据基本上都在表的前面,那么扫描范围就小,查找速度就快,如果极端情况下都在表的尾部,那么要扫描到后面才能返回所需的数据,自然就慢。这种情况下保持统计信息的及时更新和在那个列上创建非聚集索引“可能”对查询有帮助。这跟同一个查询语句,只是order by一个列,一个是desc一个是asc相类似。这时也经常会出现性能差异。
再看一次你的执行计划,然后百分比主要在关联,但是我个人认为是函数惹的祸,你看第一个查询的执行计划,那个函数处理的表没索引,而且数据量大(看箭头的粗细,1000多行就那么一点,估计那个函数处理的表应该有10万级别),扫描这么大个表,又没有索引辅助,慢是很正常。
另外第二个查询用到了并行度,也就是这个时候可是借助多CPU来计算,对速度提升也有一定程度的帮助。
------解决方案--------------------
http://www.cnblogs.com/CareySon/archive/2013/01/09/2853094.html
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
