<!--摘要-->
例如上表(stu)中显示的内容,需要查询sma列第三高的SQL语句如下 select a.* from (select rank() over(order by sma desc) as rk,stu.* from stu)a where a.rk=3; 查询结果如下 通过浏览全表不难发现,在表中sma值第三高的为20,并且不只是一个。结果显示正确。 rank() 针对over()函数中的排列,排序顺序产生对应over规则的的阶层,如果只执行 select rank() over(order by sma desc) as rk,stu.* from stu,那么结果集如下。 发现第一列也就是RK(rank产生阶层的列)已经针对over()函数中的条件产生了阶层值,我们只需要取出对应阶层值的数据即可。无需关心重复问题。 如果不考虑重复,只考虑是第几个 select a.* from (select row_number() over(order by sma desc) as rk,stu.* from stu)a where a.rk=3; select * from(select t.*,rownum nu from (select * from stu order by sma)t)e where e.nu=3; 两种写法都OK,第一种会更效率、
<!--如果有语音信息,显示数量-->
<!--详情-->
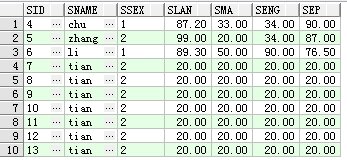
例如上表(stu)中显示的内容,需要查询sma列第三高的SQL语句如下
select a.* from (select rank() over(order by sma desc) as rk,stu.* from stu)a where a.rk=3;
查询结果如下

通过浏览全表不难发现,在表中sma值第三高的为20,并且不只是一个。结果显示正确。
?
rank() 针对over()函数中的排列,排序顺序产生对应over规则的的阶层,如果只执行
select rank() over(order by sma desc) as rk,stu.* from stu,那么结果集如下。
 发现第一列也就是RK(rank产生阶层的列)已经针对over()函数中的条件产生了阶层值,我们只需要取出对应阶层值的数据即可。无需关心重复问题。
发现第一列也就是RK(rank产生阶层的列)已经针对over()函数中的条件产生了阶层值,我们只需要取出对应阶层值的数据即可。无需关心重复问题。
如果不考虑重复,只考虑是第几个
select a.* from (select row_number() over(order by sma desc) as rk,stu.* from stu)a where a.rk=3;
?select * from(select t.*,rownum nu from (select * from stu order by sma)t)e where e.nu=3;
两种写法都OK,第一种会更效率

