exists跟in
日期:2014-05-16 浏览次数:20403 次
in
针对in很好理解,
 ?
?
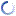
- select?*?from?T1?where?T1.a?in?(select?T2.a?from?T2)?”?????
select * from T1 where T1.a in (select T2.a from T2) ”
?
这里的“in”后面括号里的语句搜索出来的字段的内容一定要相对应,一般来说,T1和T2这两个表的a字段表达的意义应该是一样的,否则这样查没什么意义。
exists:
?
- select?*?from?T1?where?exists(select?1?from?T2?where?T1.a=T2.a)?;?????
select * from T1 where exists(select 1 from T2 where T1.a=T2.a) ;
?
T1数据量小而T2数据量非常大时,T1<<T2 时,1) 的查询效率高。
刚开始有点不理解为啥是select 1,后来一想,最根本的原因是不能按照in的思路去考虑exists
?
通过使用EXISTS,Oracle会首先检查主查询,然后运行子查询直到它找到第一个匹配项,这就节省了时间。
Oracle在执行IN子查询时,首先执行子查询,并将获得的结果列表存放在一个加了索引的临时表中。在执行子查询之前,
系统先将主查询挂起,待子查询执行完毕,存放在临时表中以后再执行主查询。这也就是使用EXISTS比使用IN通常查询速度快的原因。
---------------------------------------------------------
?
??? exists 适合外表的结果集小的情况。因为in 是把外表和那表作hash join,而exists是对外表作loop,每次loop再对那表进行查询。
??? 当 exists 中的 where 后面条件为真的时候则把前面select 的内容显示出来(外表的select ).
??? 这样的话,in适合内外表都很大的情况,exists适合外表结果集很小的情况。
?
---------------------------------------------------------
in和exists
in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。一直以来认为exists比in效率高的说法是不准确的。
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
例如:表A(小表),表B(大表)
1:
select * from A where cc in (select cc from B) 效率低,用到了A表上cc列的索引;
select * from A where exists(select cc from B where cc=A.cc) 效率高,用到了B表上cc列的索引。
相反的2:
select * from B where cc in (select cc from A) 效率高,用到了B表上cc列的索引;
select * from B where exists(select cc from A where cc=B.cc) 效率低,用到了A表上cc列的索引。
not in 和not exists如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
in 与 =的区别
select name from student where name in ('zhang','wang','li','zhao');
与
select name from student where name='zhang' or name='li' or name='wang' or name='zhao'
的结果是相同的。
