数据库170w条数据,对目录列查询较慢,求优化建议
日期:2014-05-17 浏览次数:20562 次
数据库170w条数据,对索引列查询较慢,求优化建议
有一个文章表(id title url body...等)
网址列 url: nvarchar(200), 建了唯一 、非聚集索引
body:ntext
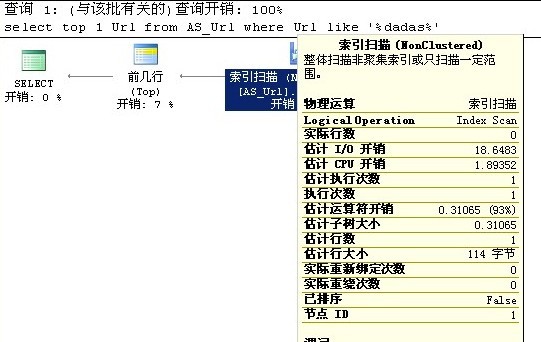
现在总数据量180w,对url列进行模糊查询 select top 1 Url from [tb] where Url like '%dadas%' 。耗时11秒
求解决方法
------解决方案--------------------
like '%xxx%'是无法利用索引了
只能通过其他条件先缩小范围了
------解决方案--------------------
1、like '%dadas%'丢失索引。如果要改进,用全文索引
2、nvarchar这些大类型对索引的性能依赖不强,很难有什么提升。
综上所述:用全文索引
------解决方案--------------------
是否利用索引和你的selectivity有关,和用不用like无关
------解决方案--------------------
百分号在前面就用不了索引
------解决方案--------------------
correct
------解决方案--------------------
uncertainty
如果like百分号在前面就用不了索引,如果like百分号不在前面,會根據你的selectivity[选择率 = (唯一索引值的个数)/ (表中所有行数)],再做選擇是否用索引.
------解决方案--------------------
从设计角度避免使用 like '%abc%'的形式
即使要模糊查找,至少也应该是 like 'abc%'
有一个文章表(id title url body...等)
网址列 url: nvarchar(200), 建了唯一 、非聚集索引
body:ntext
现在总数据量180w,对url列进行模糊查询 select top 1 Url from [tb] where Url like '%dadas%' 。耗时11秒
求解决方法
------解决方案--------------------
like '%xxx%'是无法利用索引了
只能通过其他条件先缩小范围了
------解决方案--------------------
1、like '%dadas%'丢失索引。如果要改进,用全文索引
2、nvarchar这些大类型对索引的性能依赖不强,很难有什么提升。
综上所述:用全文索引
------解决方案--------------------
是否利用索引和你的selectivity有关,和用不用like无关
------解决方案--------------------
百分号在前面就用不了索引
------解决方案--------------------
correct
------解决方案--------------------
uncertainty
如果like百分号在前面就用不了索引,如果like百分号不在前面,會根據你的selectivity[选择率 = (唯一索引值的个数)/ (表中所有行数)],再做選擇是否用索引.
------解决方案--------------------
从设计角度避免使用 like '%abc%'的形式
即使要模糊查找,至少也应该是 like 'abc%'
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
