怎样将爬虫佯装像浏览器
日期:2014-05-17 浏览次数:21352 次
怎样将爬虫伪装像浏览器
小弟写了爬虫爬豆了个瓣的网页数据(不用登录),不一会儿就403错误了。
蛋四!通过浏览器还能正常访问!而且浏览器多刷新几次都没问题,爬虫程序是连一次请求都无法获取。
因此我得出结论:我的爬虫too young too simple,和正常浏览器行为不一样。
我想请问,怎样伪装爬虫,使它像一个浏览器,不被服务器封呢?(我知道有请求频率限制,暂时不考虑这点,肯定还有其他)
我上网查了部分资料,说需要加头部。我用chrome浏览器抓到了头部的信息(应该是吧?):
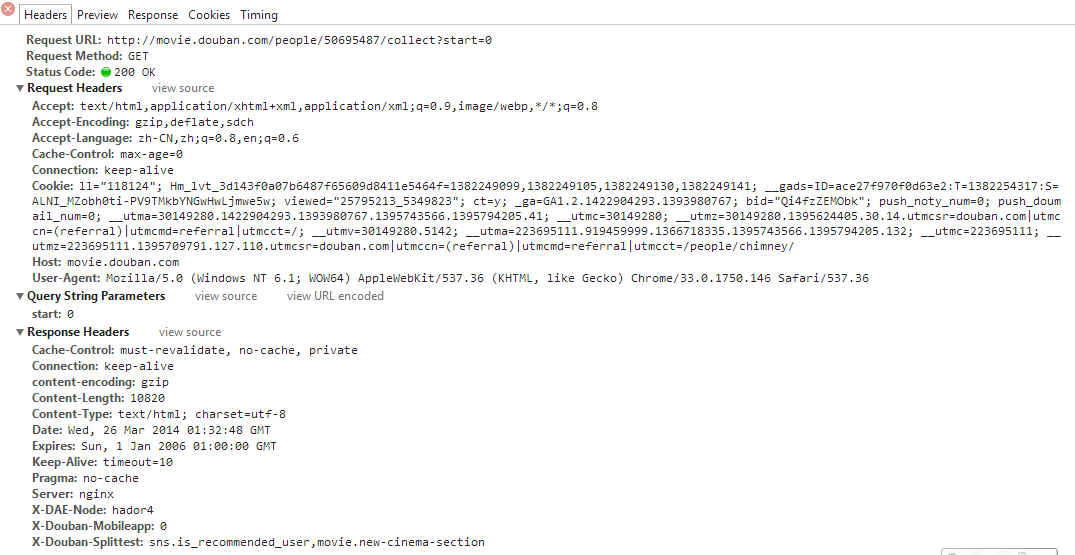
然后这是我的程序:
结果还是403。
见过论坛一个旧帖:
http://bbs.csdn.net/topics/360161423
发现他也没有解决,最后用的是代理IP。但我用代理实在是太慢了。况且理论上讲,把爬虫伪装好,应该能像浏览器一样成功访问吧?
请各位大神指点迷津。。。
------解决方案--------------------
破解城堡最好是看看城堡是如何进行防御的
------解决方案--------------------
一个是模拟点击,另外一个IP一定要换的。
你刷新个浏览器才多少链接,跟爬虫不一样啊。
关于IP没有什么好方法来伪装,用免费代理一般都很慢,浪费资源。而且现在代理也可以被查。
最好用路由拨号,隔一阵就断开重连。
------解决方案--------------------
请求完后使用httpGet.abort()断开连接,也许是因为你没断开,导致维持了许多连接,然后被封了
httpget.releaseConnection()会清理session,一般不用,或者在最后用。
小弟写了爬虫爬豆了个瓣的网页数据(不用登录),不一会儿就403错误了。
蛋四!通过浏览器还能正常访问!而且浏览器多刷新几次都没问题,爬虫程序是连一次请求都无法获取。
因此我得出结论:我的爬虫too young too simple,和正常浏览器行为不一样。
我想请问,怎样伪装爬虫,使它像一个浏览器,不被服务器封呢?(我知道有请求频率限制,暂时不考虑这点,肯定还有其他)
我上网查了部分资料,说需要加头部。我用chrome浏览器抓到了头部的信息(应该是吧?):
然后这是我的程序:
public String loadPage(String url)
{
String data = null;
System.out.println("Requesting: " + url);
try {
HttpGet httpget = new HttpGet(url);
httpget.setHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
httpget.setHeader("Accept-Encoding", "gzip,deflate,sdch");
httpget.setHeader("Accept-Language", "zh-CN,zh;q=0.8,en;q=0.6");
httpget.setHeader("Cache-Control", "max-age=0");
httpget.setHeader("Connection", "keep-alive");
httpget.setHeader("Host", "movie.douban.com");
httpget.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36");
HttpResponse response = httpClient.execute(httpget);
System.out.println(response.getStatusLine());
data = EntityUtils.toString(response.getEntity());
// httpget.releaseConnection();
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return data;
}
结果还是403。
见过论坛一个旧帖:
http://bbs.csdn.net/topics/360161423
发现他也没有解决,最后用的是代理IP。但我用代理实在是太慢了。况且理论上讲,把爬虫伪装好,应该能像浏览器一样成功访问吧?
请各位大神指点迷津。。。
------解决方案--------------------
破解城堡最好是看看城堡是如何进行防御的
------解决方案--------------------
一个是模拟点击,另外一个IP一定要换的。
你刷新个浏览器才多少链接,跟爬虫不一样啊。
关于IP没有什么好方法来伪装,用免费代理一般都很慢,浪费资源。而且现在代理也可以被查。
最好用路由拨号,隔一阵就断开重连。
------解决方案--------------------
请求完后使用httpGet.abort()断开连接,也许是因为你没断开,导致维持了许多连接,然后被封了
httpget.releaseConnection()会清理session,一般不用,或者在最后用。
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
