关于java中文编码有关问题
日期:2014-05-20 浏览次数:21174 次
关于java中文编码问题
字符串“I am 君山”用 ISO-8859-1 编码,下面是编码结果:
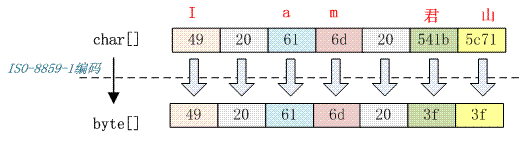
为什么【君】字编码541b会转换成3f?中间怎么转换的?
------解决方案--------------------
Java内部使用的是UTF-16来表达一个字符(两个字节),其值范围是[0, 65535]
而ISO8859-1使用的是ASCII码,其值是[0, 255]
当String.getBytes()的编码是ISO8859-1时,String的每个字符都会对应的生成一个byte, 这样,超出255范围的,一个byte不能处理,所以用3f (?) 来表示处理不了。
而其他编码,如UTF-8, GB2312是多字节表示的,所以在String.getBytes()时,会对应的处理成多字节。
------解决方案--------------------
比如我新建一个test.txt,输入你的字符串,然后用UE的16进制查看:

就看到的是BE FD C9 BD。
楼主的char[]是怎么得来的?
------解决方案--------------------
我是这么理解的。
1、java中的一个char是两个字节,“君”可以用char表示,下面的代码,打印出来就是541b.
2、ISO-8859-1有个编码表,它查了半天也不认识“君”,就用3f表示了。
3、GB2312有个码表,里面存的有“君”、“山”这样的东西,一查就找到了,就把查到的东西给你了,就是befd。
《深入分析Java Web技术内幕》 。
。
------解决方案--------------------
【君】对应的是unicode编码中的541b;在GB2321中对应的编码为be fd,就是一个对应关系,不是通过算法什么的转化的;具体的unicode编码表可以参考:http://blog.csdn.net/gaohongijj/article/details/9208103
字符串“I am 君山”用 ISO-8859-1 编码,下面是编码结果:
为什么【君】字编码541b会转换成3f?中间怎么转换的?
Java
编码
------解决方案--------------------
Java内部使用的是UTF-16来表达一个字符(两个字节),其值范围是[0, 65535]
而ISO8859-1使用的是ASCII码,其值是[0, 255]
当String.getBytes()的编码是ISO8859-1时,String的每个字符都会对应的生成一个byte, 这样,超出255范围的,一个byte不能处理,所以用3f (?) 来表示处理不了。
而其他编码,如UTF-8, GB2312是多字节表示的,所以在String.getBytes()时,会对应的处理成多字节。
------解决方案--------------------
比如我新建一个test.txt,输入你的字符串,然后用UE的16进制查看:
就看到的是BE FD C9 BD。
楼主的char[]是怎么得来的?
------解决方案--------------------
我是这么理解的。
1、java中的一个char是两个字节,“君”可以用char表示,下面的代码,打印出来就是541b.
char c = '君';
System.out.println(Integer.toString(c, 16));
2、ISO-8859-1有个编码表,它查了半天也不认识“君”,就用3f表示了。
3、GB2312有个码表,里面存的有“君”、“山”这样的东西,一查就找到了,就把查到的东西给你了,就是befd。
《深入分析Java Web技术内幕》
。------解决方案--------------------
【君】对应的是unicode编码中的541b;在GB2321中对应的编码为be fd,就是一个对应关系,不是通过算法什么的转化的;具体的unicode编码表可以参考:http://blog.csdn.net/gaohongijj/article/details/9208103
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
