oracle关联查询加group by自动去掉重复数据有关问题
日期:2014-05-17 浏览次数:21675 次
oracle关联查询加group by自动去掉重复数据问题
select u.name from s_user u,s_role r where u.id = r.user_id
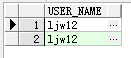
select u.name from s_user u,s_role r where u.id = r.user_id
group by u.name
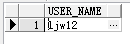
就加了个group by u.name 然后就把u.name里的数据重复的去掉了!
单表查的时候不会出现这种问题!
求解释一下!
------解决方案--------------------
加了 group by u.name 是按 u.name 进行分组,自然查询结果不会有重复的 u.name
------解决方案--------------------
+1 既然是分组,如果查询结果两条相同,肯定会分为一组啊。
------解决方案--------------------
没错
------解决方案--------------------
用group by是将查询字段中相同的值,作为一组,不管你要查询的字段的值有多少个相同(其他字段可以不相同),都会将其归为一组,查询结果都不会有重复。
------解决方案--------------------
恩,分组函数么,相同就喝到一起了。
------解决方案--------------------
是你的关联表引起的
你关联的s_role表应该有两条相同的user_id,它们对应表s_user 一条ID
select u.name from s_user u,s_role r where u.id = r.user_id
select u.name from s_user u,s_role r where u.id = r.user_id
group by u.name
就加了个group by u.name 然后就把u.name里的数据重复的去掉了!
单表查的时候不会出现这种问题!
求解释一下!
------解决方案--------------------
加了 group by u.name 是按 u.name 进行分组,自然查询结果不会有重复的 u.name
------解决方案--------------------
+1 既然是分组,如果查询结果两条相同,肯定会分为一组啊。
------解决方案--------------------
没错
------解决方案--------------------
用group by是将查询字段中相同的值,作为一组,不管你要查询的字段的值有多少个相同(其他字段可以不相同),都会将其归为一组,查询结果都不会有重复。
------解决方案--------------------
恩,分组函数么,相同就喝到一起了。
------解决方案--------------------
是你的关联表引起的
你关联的s_role表应该有两条相同的user_id,它们对应表s_user 一条ID
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
