html解析的正则表达式
日期:2014-05-17 浏览次数:21377 次
html解析的正则表达式,求助
C#读取了一个网页,其中片段:
。。。。
<div>
<ul>
<dt>a</dt>
<dd>a1</dd>
<dt>b</dt>
<dd>b1</dd>
<dt>c</dt>
<dd>c1</dd>
</ul>
</div>
。。。
如何通过正则表达式,获取以下片段?
<dt>a</dt>
<dd>a1</dd>
<dt>b</dt>
<dd>b1</dd>
------解决方案--------------------
你有什么规则么 我就随便写个了 也许不是你想要的
<(dt
------解决方案--------------------
dd)>(a1?
------解决方案--------------------
b1?)</(dt
------解决方案--------------------
dd)>
------解决方案--------------------
(?i)<(d[td])>[^<>]+</\1>
------解决方案--------------------
(?s)(?<=<ul[^>]*>)(?:\s*<dt\b[^>]*>(?:(?!</dd\b).)*</dd>\s*){2}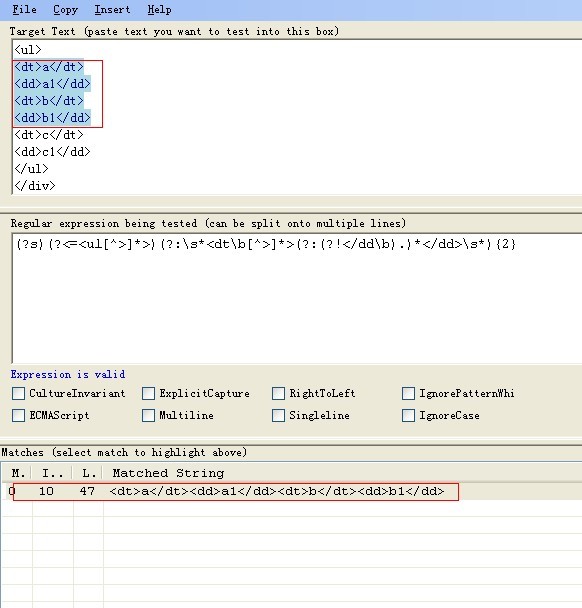
------解决方案--------------------
string str="字符串";
str = Regex.Match(str, @"(?is)(?<=<ul>)(\s*<(\w+)[^>]*>.*?</\2>){1,4}").Value;
------解决方案--------------------
html解析就是html解析,不要扯上“正则”。
你可以搜索一下“.net平台html解析工具”,看看都有什么解析html的软件包可以在编程中调用。
反之,如果你是问正则表达式,那么就不要说什么“html解析”了。只是匹配简单的字母,跟进行正确的语法分析从而得到html elements树相比,实在是“泥土与陶瓷”的区别。
C#读取了一个网页,其中片段:
。。。。
<div>
<ul>
<dt>a</dt>
<dd>a1</dd>
<dt>b</dt>
<dd>b1</dd>
<dt>c</dt>
<dd>c1</dd>
</ul>
</div>
。。。
如何通过正则表达式,获取以下片段?
<dt>a</dt>
<dd>a1</dd>
<dt>b</dt>
<dd>b1</dd>
------解决方案--------------------
你有什么规则么 我就随便写个了 也许不是你想要的
<(dt
------解决方案--------------------
dd)>(a1?
------解决方案--------------------
b1?)</(dt
------解决方案--------------------
dd)>
------解决方案--------------------
(?i)<(d[td])>[^<>]+</\1>
------解决方案--------------------
(?s)(?<=<ul[^>]*>)(?:\s*<dt\b[^>]*>(?:(?!</dd\b).)*</dd>\s*){2}
------解决方案--------------------
string str="字符串";
str = Regex.Match(str, @"(?is)(?<=<ul>)(\s*<(\w+)[^>]*>.*?</\2>){1,4}").Value;
------解决方案--------------------
html解析就是html解析,不要扯上“正则”。
你可以搜索一下“.net平台html解析工具”,看看都有什么解析html的软件包可以在编程中调用。
反之,如果你是问正则表达式,那么就不要说什么“html解析”了。只是匹配简单的字母,跟进行正确的语法分析从而得到html elements树相比,实在是“泥土与陶瓷”的区别。
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
