关于执行计划的解读,汇聚索引,in的方式查询
日期:2014-05-17 浏览次数:20879 次
关于执行计划的解读,聚集索引,in的方式查询
前几天一个一同学在QQ上问
--tableTest表,ID上建立了聚集索引
select * from tableTest where id in (1,9999,12345);
类似这样一个查询,id上有聚集索引,
应该是受到IN的查询方式用不到索引的影响,不太敢用,但试着用in的方式去执行,也不见得慢,
因为没有理论证明,所以感觉不放心,
说是全部放到in里面一次性查出来块还是一个一个地查快
所以在讨论这个问题
我首先看了IO,比如三个ID,
一个一个查,逻辑IO是3(3次就是9了),
放到in 里面一次性查询出来,逻辑IO是9
从这一点上说,IO是一样的,不存在in的方式用不到索引的问题
比一个一个查询,最起码节省了数据库连接的开销
后来我在本机sqlserver2008看了一下执行计划,就有点犯晕了,
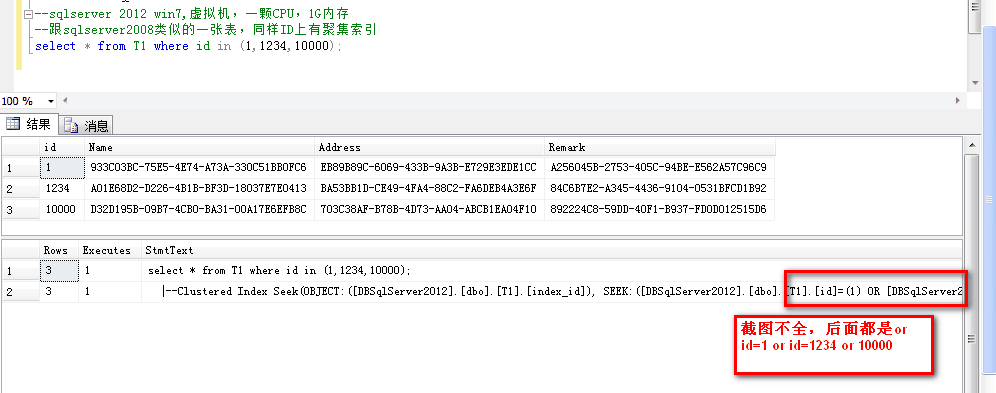
同样放到sqlserver2012下,执行计划又是不太一样的,直接上图吧
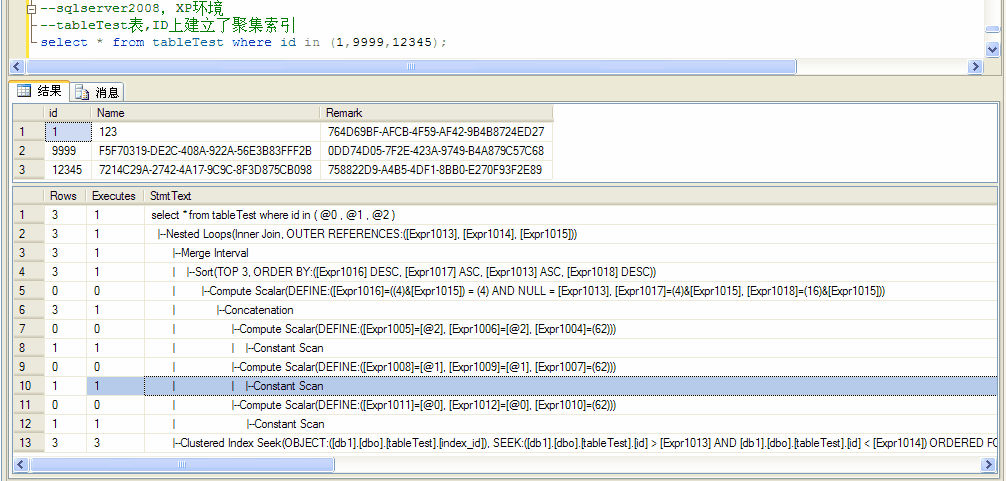
主要是搞不懂sqlserver2008下面的这个执行计划
还请大家指教
.
------解决方案--------------------
我首先看了IO,比如三个ID,
一个一个查,逻辑IO是3(3次就是9了),
放到in 里面一次性查询出来,逻辑IO是9
从这一点上说,IO是一样的,不存在in的方式用不到索引的问题
比一个一个查询,最起码节省了数据库连接的开销
首先可以肯定地说你这个查询使用in是会利用大索引的。
当然也有使用in的时候不会index seek的时候
而逻辑读取是指从缓存读取的页数,这个跟你的行大小有关系。而不是跟你的返回行数有这么明确的关系。
至于执行计划,你需要注意几个地方:
第一,每个节点返回的行数
第二,每个节点预估行数
这两点的结果对比可以判断你的执行计划是否是最优的。如果两者结果相差不大,说明SQL优化器选择的执行计划是合理的,如果有很大误差说明这个执行计划不是最优的。这个时候可能就要考虑对应的索引的问题了。可能是索引不合理,也或者是统计信息不够准确或者没来得及更新。
------解决方案--------------------
用in 不一定会用不到索引,只是可能会用不到。通过你的这个执行计划看,你的这个查询,就用到了索引,但是是否是最优的执行计划,就还需要进一步验证。
------解决方案--------------------
In的本质是or,如果大量的ID,比如上千个,可能会导致执行计划无法生成。这个我试过,2008和2012的算法的确有不同,我看过基本上的例子,然后在本机上测试的确证明了这点。
------解决方案--------------------
其实,从你贴出来的2008和2012的执行计划,能看出,同一个表,同一个聚集索引,同一个语句,所生成的执行计划却有不同:
2008的显然是采用了:
1、常量扫描-》计算标量,其实就是数据类型转化之类的 -》串联-》排序-》合并interval,这个估计有可能是去除重复
2、nested loop循环,把上面的结果,再 聚集索引中,进行index seek
而2012的,看上去非常简单,只是index seek id 加上or,也就是进行了3次index seek
说明,两者生成的执行计划,还是不同的。
前几天一个一同学在QQ上问
--tableTest表,ID上建立了聚集索引
select * from tableTest where id in (1,9999,12345);
类似这样一个查询,id上有聚集索引,
应该是受到IN的查询方式用不到索引的影响,不太敢用,但试着用in的方式去执行,也不见得慢,
因为没有理论证明,所以感觉不放心,
说是全部放到in里面一次性查出来块还是一个一个地查快
所以在讨论这个问题
我首先看了IO,比如三个ID,
一个一个查,逻辑IO是3(3次就是9了),
放到in 里面一次性查询出来,逻辑IO是9
从这一点上说,IO是一样的,不存在in的方式用不到索引的问题
比一个一个查询,最起码节省了数据库连接的开销
后来我在本机sqlserver2008看了一下执行计划,就有点犯晕了,
同样放到sqlserver2012下,执行计划又是不太一样的,直接上图吧
主要是搞不懂sqlserver2008下面的这个执行计划
还请大家指教
.
------解决方案--------------------
我首先看了IO,比如三个ID,
一个一个查,逻辑IO是3(3次就是9了),
放到in 里面一次性查询出来,逻辑IO是9
从这一点上说,IO是一样的,不存在in的方式用不到索引的问题
比一个一个查询,最起码节省了数据库连接的开销
首先可以肯定地说你这个查询使用in是会利用大索引的。
当然也有使用in的时候不会index seek的时候
而逻辑读取是指从缓存读取的页数,这个跟你的行大小有关系。而不是跟你的返回行数有这么明确的关系。
至于执行计划,你需要注意几个地方:
第一,每个节点返回的行数
第二,每个节点预估行数
这两点的结果对比可以判断你的执行计划是否是最优的。如果两者结果相差不大,说明SQL优化器选择的执行计划是合理的,如果有很大误差说明这个执行计划不是最优的。这个时候可能就要考虑对应的索引的问题了。可能是索引不合理,也或者是统计信息不够准确或者没来得及更新。
------解决方案--------------------
用in 不一定会用不到索引,只是可能会用不到。通过你的这个执行计划看,你的这个查询,就用到了索引,但是是否是最优的执行计划,就还需要进一步验证。
------解决方案--------------------
In的本质是or,如果大量的ID,比如上千个,可能会导致执行计划无法生成。这个我试过,2008和2012的算法的确有不同,我看过基本上的例子,然后在本机上测试的确证明了这点。
------解决方案--------------------
其实,从你贴出来的2008和2012的执行计划,能看出,同一个表,同一个聚集索引,同一个语句,所生成的执行计划却有不同:
2008的显然是采用了:
1、常量扫描-》计算标量,其实就是数据类型转化之类的 -》串联-》排序-》合并interval,这个估计有可能是去除重复
2、nested loop循环,把上面的结果,再 聚集索引中,进行index seek
而2012的,看上去非常简单,只是index seek id 加上or,也就是进行了3次index seek
说明,两者生成的执行计划,还是不同的。
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
