分页查询慢
日期:2014-05-17 浏览次数:21206 次
分页查询慢 求助
表中有100W条记录
第一个sql语句:select top 50 * from v_cust where reg_date>='2013-07-27' and ( code_area like '10%' or code_area='10010101') and cust_id <> '1000' and cust_id not in ( select top 850 cust_id from v_cust where reg_date>='2013-07-27' and ( code_area like '10%' or code_area='10010101') and cust_id <> '1000' order by cust_id desc) order by cust_id desc
执行需要1S
执行计划
第二个sql语句:select top 50 * from v_cust where reg_date>='2013-07-27' and ( code_area like '10%' or code_area='10010101') and cust_id <> '1000' and cust_id not in ( select top 900 cust_id from v_cust where reg_date>='2013-07-27' and ( code_area like '10%' or code_area='10010101') and cust_id <> '1000' order by cust_id desc) order by cust_id desc
执行需要70S
执行计划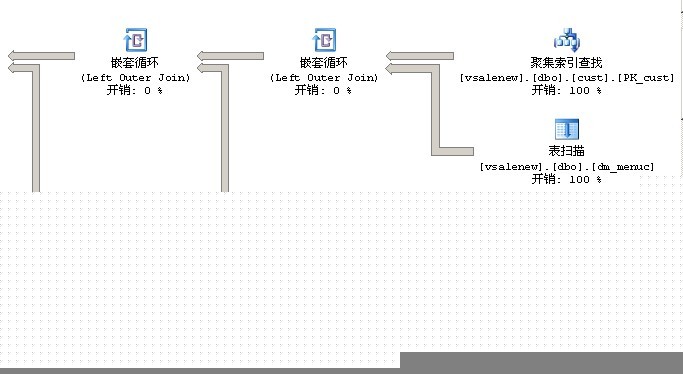
请帮我分析下是什么原因导致相差这么大
------解决方案--------------------
表中有100W条记录
第一个sql语句:select top 50 * from v_cust where reg_date>='2013-07-27' and ( code_area like '10%' or code_area='10010101') and cust_id <> '1000' and cust_id not in ( select top 850 cust_id from v_cust where reg_date>='2013-07-27' and ( code_area like '10%' or code_area='10010101') and cust_id <> '1000' order by cust_id desc) order by cust_id desc
执行需要1S
执行计划
第二个sql语句:select top 50 * from v_cust where reg_date>='2013-07-27' and ( code_area like '10%' or code_area='10010101') and cust_id <> '1000' and cust_id not in ( select top 900 cust_id from v_cust where reg_date>='2013-07-27' and ( code_area like '10%' or code_area='10010101') and cust_id <> '1000' order by cust_id desc) order by cust_id desc
执行需要70S
执行计划
请帮我分析下是什么原因导致相差这么大
------解决方案--------------------
--#1.因为没有参数化,每次查询都会重新编译,由于参数的不同,SQL SERVER产生不同的执行计划。
--第一个查询使用了表假脱机(把中间数据存储在一个临时表中以观后用),第二个查询会重复执行表扫描。这应该是效率的差别所在
--#2.这个不是偶然现象。SQL SERVER优化器会根据它的统计信息及索引情况生成他认为最优的执行计划。
--#3.你的SQL语句存在很大的问题。用到到NOT IN。如果是2005以上版本,建议如下:
SELECT * FROM
(
SELECT
rowid = ROW_NUMBER() OVER(ORDER BY cust_id DESC),
*
FROM v_cust
WHERE reg_date >= '2013-07-27'
AND code_area LIKE '10%' --10010101也属于10%,所以不用再单独写出来
AND cust_id <> 1000
) t
WHERE rowid BETWEEN 1 AND 50
--reg_date字段建立索引
--把SQL封闭成存储过程,参数化调用
--如果code_area也具有高选择性,且和reg_date字段在同一个表中,建立复合索引: reg_date,code_area
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
