关于MySQL中复合目录优化
日期:2014-05-16 浏览次数:21318 次
最近对两个开源系统进行反向工程ER图生成后,对比发现一个系统其中一个表中的复合索引的列个数对查询的效率有较大的影响~~
于是上网查了下相关的资料:(关于复合索引优化的)
两个或更多个列上的索引被称作复合索引。
利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引不同于使用两个单独的索引。复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
所以说创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
如:建立 姓名、年龄、性别的复合索引。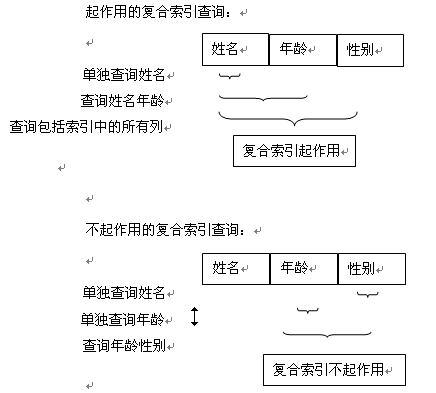
复合索引的建立原则:
如果您很可能仅对一个列多次执行搜索,则该列应该是复合索引中的第一列。如果您很可能对一个两列索引中的两个列执行单独的搜索,则应该创建另一个仅包含第二列的索引。
如上图所示,如果查询中需要对年龄和性别做查询,则应当再新建一个包含年龄和性别的复合索引。
包含多个列的主键始终会自动以复合索引的形式创建索引,其列的顺序是它们在表定义中出现的顺序,而不是在主键定义中指定的顺序。在考虑将来通过主键执行的搜索,确定哪一列应该排在最前面。
请注意,创建复合索引应当包含少数几个列,并且这些列经常在select查询里使用。在复合索引里包含太多的列不仅不会给带来太多好处。而且由于使用相当多的内存来存储复合索引的列的值,其后果是内存溢出和性能降低。
????????
复合索引对排序的优化:
复合索引只对和索引中排序相同或相反的order by 语句优化。
在创建复合索引时,每一列都定义了升序或者是降序。如定义一个复合索引:
 ?
?
- CREATE?INDEX?idx_example? ??
- ON?table1?(col1?ASC,?col2?DESC,?col3?ASC)??
CREATE INDEX idx_example ON table1 (col1 ASC, col2 DESC, col3 ASC)?
其中 有三列分别是:col1 升序,col2 降序, col3 升序。现在如果我们执行两个查询
1:Select col1, col2, col3 from table1 order by col1 ASC, col2 DESC, col3 ASC
??和索引顺序相同
2:Select col1, col2, col3 from table1 order by col1 DESC, col2 ASC, col3 DESC
?和索引顺序相反
查询1,2 都可以别复合索引优化。
如果查询为:
Select col1, col2, col3 from table1 order by col1 ASC, col2 ASC, col3 ASC
??排序结果和索引完全不同时,此时的 查询不会被复合索引优化。
查询优化器在在where查询中的作用:
如果一个多列索引存在于 列 Col1 和 Col2 上,则以下语句:Select?? * from table where?? col1=val1 AND col2=val2 查询优化器会试图通过决定哪个索引将找到更少的行。之后用得到的索引去取值。
1. 如果存在一个多列索引,任何最左面的索引前缀能被优化器使用。所以联合索引的顺序不同,影响索引的选择,尽量将值少的放在前面。
如:一个多列索引为 (col1 ,col2, col3)
??? 那么在索引在列 (col1) 、(col1 col2) 、(col1 col2 col3) 的搜索会有作用。
?
?
- SELECT?*?FROM?tb?WHERE??col1?=?val1 ??
- SELECT?*?FROM
