求个正则表达式!该如何处理
日期:2014-05-17 浏览次数:20704 次
求个正则表达式!!!!!!!
http://bbs.10jqka.com.cn/codelist.html
获取以上链接里面的部分内容
有深市、沪市、基金三种
我需要获取的是股票名称和股票代码
例如:
<li><a href="http://bbs.10jqka.com.cn/sh,600000,1" target="_blank" title="浦发银行">浦发银行 600000</a></li>
<li><a href="http://bbs.10jqka.com.cn/sh,600004,1" target="_blank" title="白云机场">白云机场 600004</a></li>
获取结果
浦发银行 600000
白云机场 600004
能直接获取成
$a=array("600000"=>"浦发银行")
这样的数组就更好了
在此先谢谢各位大神了
------解决方案--------------------
------解决方案--------------------
------解决方案--------------------
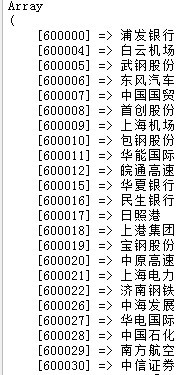
------解决方案--------------------
$url ="http://bbs.10jqka.com.cn/codelist.html";
$str = file_get_contents($url);
$str = iconv('gbk', 'utf-8', $str);
preg_match_all('/<li><a[^>]+>([^\d]+)(\d{6})<\/a><\/li>/isU',$str,$match);
$a = array_combine(array_values($match[2]),array_values($match[1]));
print_r($a);
http://bbs.10jqka.com.cn/codelist.html
获取以上链接里面的部分内容
有深市、沪市、基金三种
我需要获取的是股票名称和股票代码
例如:
<li><a href="http://bbs.10jqka.com.cn/sh,600000,1" target="_blank" title="浦发银行">浦发银行 600000</a></li>
<li><a href="http://bbs.10jqka.com.cn/sh,600004,1" target="_blank" title="白云机场">白云机场 600004</a></li>
获取结果
浦发银行 600000
白云机场 600004
能直接获取成
$a=array("600000"=>"浦发银行")
这样的数组就更好了
在此先谢谢各位大神了
正则表达式
------解决方案--------------------
preg_match_all('/<li><a[^>]+>(.+)<\/a><\/li>/isU',$s,$m);
print_r($m[1]);------解决方案--------------------
$str=<<<STR
<li><a href="http://bbs.10jqka.com.cn/sh,600000,1" target="_blank" title="浦发银行">浦发银行 600000</a></li>
<li><a href="http://bbs.10jqka.com.cn/sh,600004,1" target="_blank" title="白云机场">白云机场 600004</a></li>
STR;
preg_match_all("/(\S+)\s+(\d+)/",preg_replace("/<\/?[^>]+?>/",'',$str),$out,PREG_SET_ORDER);
foreach($out as $a) list($s,$o[$i],$i)=$a;
print_r($o);
------解决方案--------------------
<?php
$url ="http://bbs.10jqka.com.cn/codelist.html";
$str = file_get_contents($url);
preg_match_all('/<li><a[^>]+>([^\d]+)(\d{6})<\/a><\/li>/isU',$str,$match);
$a = array_combine(array_values($match[2]),array_values($match[1]));
print_r($a);
------解决方案--------------------
$url ="http://bbs.10jqka.com.cn/codelist.html";
$str = file_get_contents($url);
$str = iconv('gbk', 'utf-8', $str);
preg_match_all('/<li><a[^>]+>([^\d]+)(\d{6})<\/a><\/li>/isU',$str,$match);
$a = array_combine(array_values($match[2]),array_values($match[1]));
print_r($a);
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
