两三周之前遇到的一个问题,终于在今天解决,感觉心情舒畅啊!
?
hibernate查询数据库时,不知道什么原因变得非常的慢,但是同样的代码在另外的服务器上却一点问题也不慢。一直以为是内存的原因,因为生产用的服务器的内存不记得是32G还是64G的了,自己的电脑是2G而且还是远程操作,再加上要做其他任务开发,所以一直没有踏实地去解决这个问题。过去的两周里都是在刷页面,打开一个主要页面要等20分钟左右,有时候要多登录不同的用户进行测试则需要等上1个小时,如果测试不通过,又得再等一个小时,这开发效率极慢,所以只好加班加点地把开发任务做完。
近两天,终于做完开发任务,便开始主攻这个hibernate查询缓慢的问题。
关于这个问题,咨询过很多同事,以及IT行业的同学朋友
主要朝下面几个方向去思考解决:
1,SQL调优,建索引
2,代码是否设计合理
3,查看LOG日志文件,hibernate查询语句的输出
4,N+1问题
?
因为半路出家进入程序猿行业,所以前面的1、2未作为第一选择,3也查看了发现有许多的select语句,后确定是N+1问题。
?
?
如果当SQL数据库中select语句数目过多,就会影响数据库的性能,如果需要查询n个Customer对象,那么必须执行n+1次select查询语句,下文就将为您讲解这个n+1次select查询问题。
在Session的缓存中存放的是相互关联的对象图。默认情况下,当Hibernate从数据库中加载Customer对象时,会同时加载所有关联的Order对象。以Customer和Order类为例,假定ORDERS表的CUSTOMER_ID外键允许为null,图1列出了CUSTOMERS表和ORDERS表中的记录。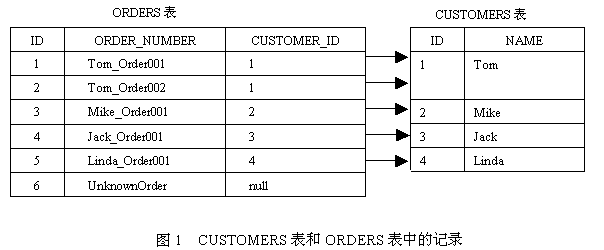
以下Session的find()方法用于到数据库中检索所有的Customer对象:
List customerLists=session.find("from Customer as c");
运行以上find()方法时,Hibernate将先查询CUSTOMERS表中所有的记录,然后根据每条记录的ID,到ORDERS表中查询有参照关系的记录,Hibernate将依次执行以下select语句:
select * from CUSTOMERS;?
select * from ORDERS where CUSTOMER_ID=1;
select * from ORDERS where CUSTOMER_ID=2;
select * from ORDERS where CUSTOMER_ID=3;
select * from ORDERS where CUSTOMER_ID=4;
?
?
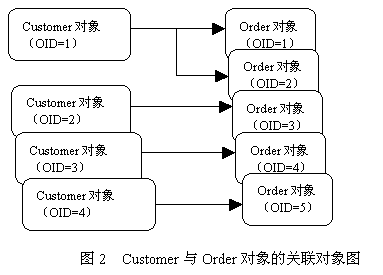 Hibernate在检索与Customer关联的Order对象时,使用了默认的立即检索策略。这种检索策略存在两大不足:
Hibernate在检索与Customer关联的Order对象时,使用了默认的立即检索策略。这种检索策略存在两大不足:
(1) select语句的数目太多,需要频繁的访问数据库,会影响检索性能。如果需要查询n个Customer对象,那么必须执行n+1次select查询语句。这就是经典的n+1次select查询问题。这种检索策略没有利用SQL的连接查询功能,例如以上5条select语句完全可以通过以下1条select语句来完成:
