读淘宝数据库架构之体验
日期:2014-05-16 浏览次数:20714 次
读淘宝数据库架构之体会
体会如下
原文档下载地址:点击打开链接
体会如下
1.SQL语句复杂程度由繁到简

多表关联查询致使应用的耦合性偏高,不利于数据的分布式拆分部署。在执行查询时,如遇代理对象,对数据的远程传递和缓存都会产生影响(代理对象无法序列化,代理方法执行时找不到session)。打散库表关系后,对数据库的访问主要通过主键ID来完成,其他查询方法可通过倒排索引库来操作。
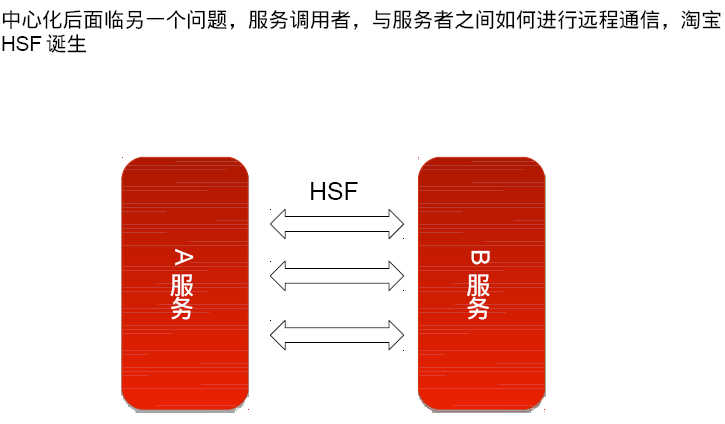
系统发展到一定规模后所处理的服务会越来越多,系统负荷也会逐渐增大,这时需要考虑把负荷比较大的服务独立出去,单独部署,然后通过远程通信的方式调用该服务。拆分服务的同时还可将底层对应的数据独立出去,缓解主数据库的访问压力。在服务的拆分部署上OSGI RemoteService是不错的选择。
3.数据库的读写分离
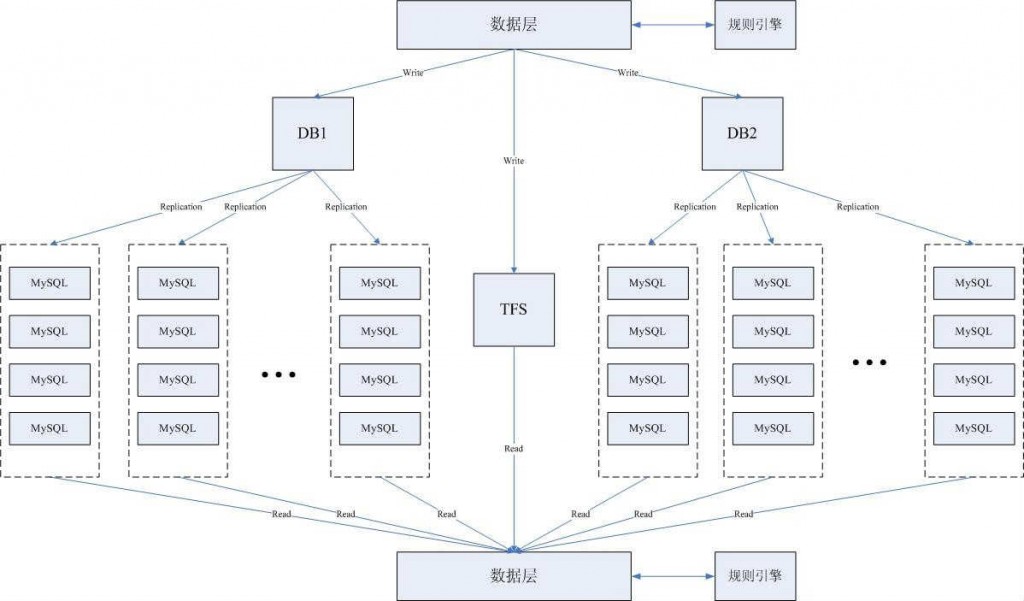
当单台数据库的吞吐量较大时,可考虑引入集群来分散压力,同时对读写操作进行分离,引入两套不同的DAO操作不同的数据库,比较难于处理的是如何做好数据库之间的数据迁移。
4.不同的读服务,不同的读载体
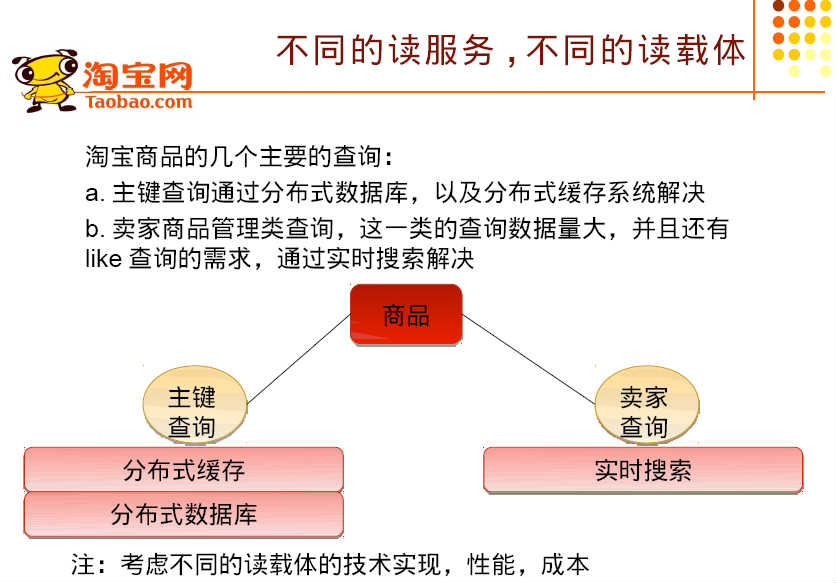
对于淘宝这种信息发布类型的网站,信息的检索方式主要有两种,一种是通过主键ID的方式来进行数据检索,还有一种是通过模糊匹配的方式进行数据查询。针对第一种方式,通常的做法是通过引入缓存来提升数据的检索效率并缓解数据库的访问压力;而第二种方式通常采用的方法是倒排索引,比如通过Lucence来检索数据。
5.分布式缓存

缓存是用来提升系统响应速度的有效途径之一,除了淘宝自身研发的tair,比较常用的缓存工具还有memcached。
免责声明: 本文仅代表作者个人观点,与爱易网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
