activeMQ 的kahadb储存引擎分析
日期:2014-05-16 浏览次数:20768 次
很久没更新blog了,前几天看到淘宝开源了Meta,估计notify也要开源了。其实消息中间件的一个非常重要的核心部件就是持久化存储,可能Meta的功能定位使得它在这一块的实现相对notify和activemq就简单些。趁着有点时间,把activeMQ的kahadb存储引擎做了个分析,希望能对jms实现感兴趣的朋友有点帮助。
1. 概述
Kahadb是activemq从版本5.4之后的默认消息存储引擎。消息存储机制是消息中间件最重要的核心部件和性能提升点。一直想对它做一个完整分析,这次趁有时间对kahadb做一个较完整分析。
Kahadb是基于B-tree算法的,具体原理fusesource给了个原理说明(http://fusesource.com/docs/broker/5.4/persistence/KahaDB-Overview.html),下面我们从代码实现角度进行一个较深入的分析。下面所有的分析都是基于activeMQ 5.4.3版本源码,该版本里的kahadb版本是V3,且是基于queue进行的源码分析,topic的实现虽然有不少差异,但整体可参考queue的。
2. 每个磁盘文件的作用和详细存储格式
首先kahadb在消息保存目录中只有4类文件和一个lock,跟ActiveMQ的其他几种文件存储引擎相比这就非常简洁了。
每种文件的具体作用:
#db-*.log:
存放完整的每条消息(包括事务、目的地、id、优先级、具体内容等)和producerSequenceIdTracker(用来验证每个消息生成者发送的消息是否重复的数据结构)。它随着消息数量的增多,如每32M一个文件,文件名按照数字进行编号,如db-1.log、db-2.log、db-3.log …
#db.data
通过存放多个Btree数据结构来保存各类重要信息,下面一一进行介绍:
? Metadata类的destinations:用来保存该broker上有哪些Queue或队列
? StoredDestination类的orderIndex属性中的
defaultPriorityIndex、lowPriorityIndex、highPriorityIndex,这3个btree是为消息优先级排序而设计的(应该是版本5.4引入的,唉,有时候一个功能的引入带来的代价可能比较大)。它们的主要作用是为AbstractStoreCursor类的doFillBatch方法服务的,也就是常说的消息指针(message cursors)。当消息指针需要从磁盘文件中装载一批消息的时候会使用这3个btree实例(kahadb版本小于2的不支持lowPriorityIndex、highPriorityIndex)
? StoredDestination类的locationIndex:该btree的主要作用包括:
. 系统重启进行恢复操作的时候,要移除掉不在db-*.log文件里的消息;
. 在系统进行定时checkpointUpdate时使用
? StoredDestination类的messageIdIndex:该btree的主要作用是消息确认acknowledge操作时,通过消息ID在messageIdIndex中删除对应的记录,并依据返回的值删除orderIndex和locationIndex中的记录
上面这些就是kahadb中最主用的btree实例。
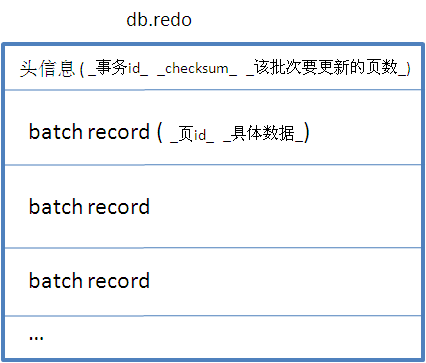
#db.redo
它的作用是“Double Write”,具体代码参看PageFile类的writeBatch方法。它的原理可参考(http://www.mysqlperformanceblog.com/2006/08/04/innodb-double-write/)
#db.free
当前db.data文件里哪些页面是空闲的,文件具体内容是所有空闲页的ID
下面是具体每个文件的内部数据格式: